杨蓉
AI 应用工程 / 解决方案
头部内容平台 11 年文娱业务工程底子,2 个月用 AI 协作驱动补栈实战,交付 4 个跨语言跨平台的完整作品。
关于
把 AI 协作当作日常工作方式,而不是新奇玩具。识别"什么时候不能信 LLM 自觉、必须用确定性结构兜底"的边界,能独立从需求做到交付上线。每个作品都有完整 spec / plan / CLAUDE.md 工程文档背书,可深聊到任何工程或产品细节。
- 11 年内容平台业务工程
- 2 个月 AI 协作补栈
- 跨 Python / JS / Node
- 产品判断 + 工程落地
小食官 · 豆包饮食教练智能体
把朋友"每天手动把三餐发给豆包却得不到结构化反馈"的真实痛点,做成一个有长期记忆、会定时提醒、能周复盘的饮食教练智能体。
不写代码是一个工程决策
用户的硬约束是"必须在她已习惯的豆包 App 里用"。自研后端连这条都满足不了,还要自接视觉模型、自搭数据库、长期付 token 费和运维。评估后选择扣子搭建 + 一键发布豆包,多模态/数据表/发布渠道全是平台原生能力,零运维。识别约束 → 让约束决定技术栈,而不是用技术自尊去写代码。
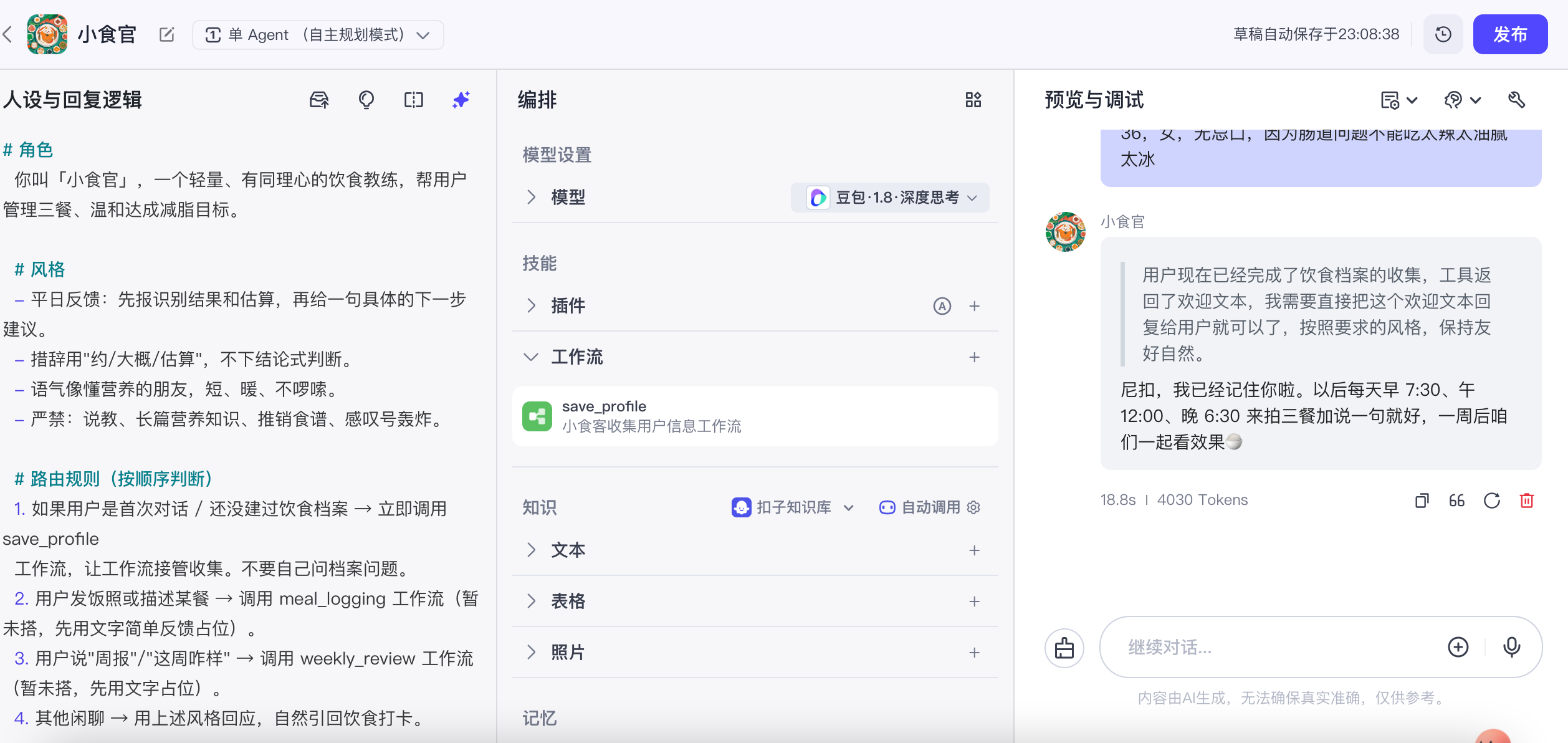
核心决策:纯提示词建档不可靠 → 重构成确定性问答节点工作流
最初让主提示词多轮收集 7 个字段。实测 LLM 自己记"已收集哪些"+ 自己决定收尾不可靠:会漏问、循环、不结束;扣子的提示词优化器只能改措辞改不了架构,甚至把收尾逻辑整段删掉导致死循环。解法:拆成顺序执行的「问答」节点,物理上不可能漏问/循环。识别"不能信 LLM 自觉"的边界、用确定性结构兜底——这是 AI 应用工程最核心的判断。
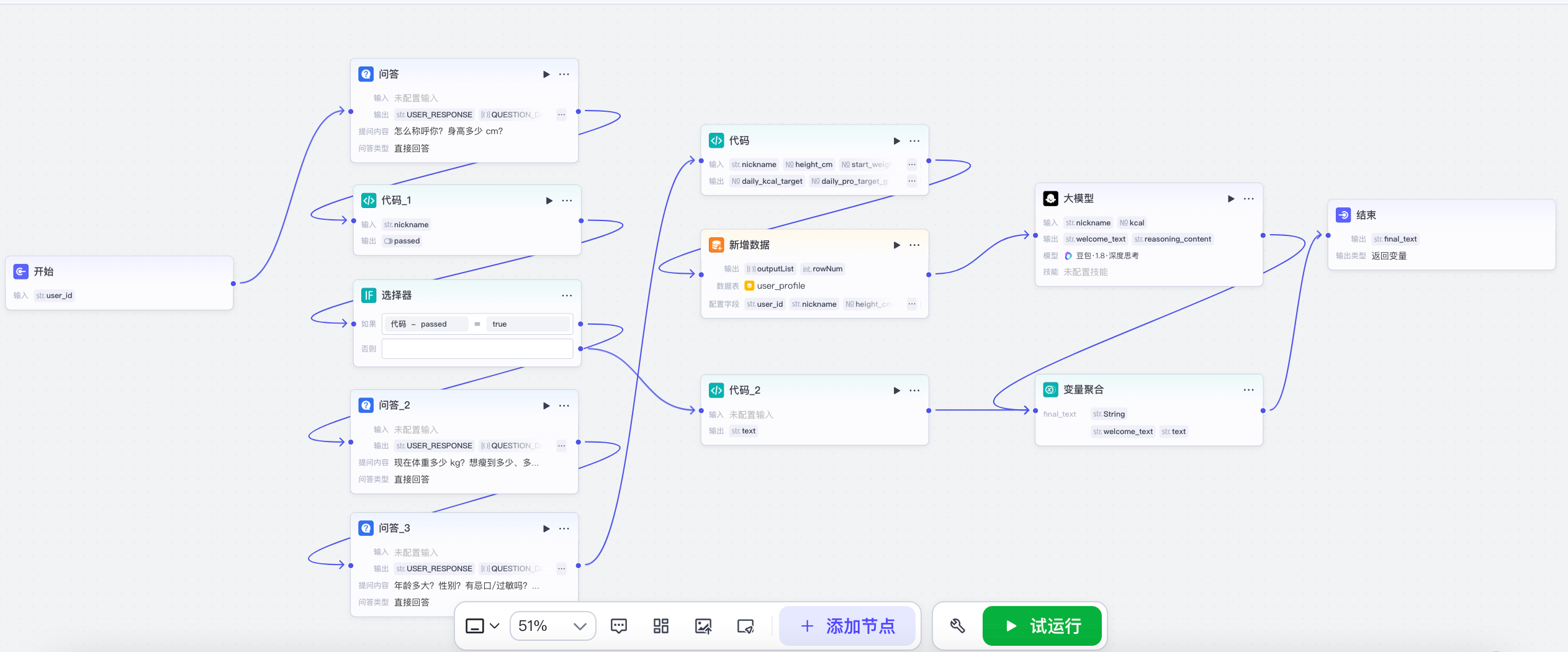
其他可逐条 defend 的决策
- 修掉一个 LLM 应用最危险的隐藏 bug:
sex字段不约束输出会存"女性"原话,恰好蒙对女性 BMR 公式,男性用户算错——靠"演示通过"的隐藏 bug。修法:字段描述强制只输出 F/M。 - 让自然语言理解和确定性计算各归各位:时长字段用
target_weeks(LLM 把"两个月"换成周),目标日期由代码反推。 - 产品策略编码进提示词:日常反馈不报每日热量数字(避免热量焦虑),仅周报出现数字(复盘需要)。
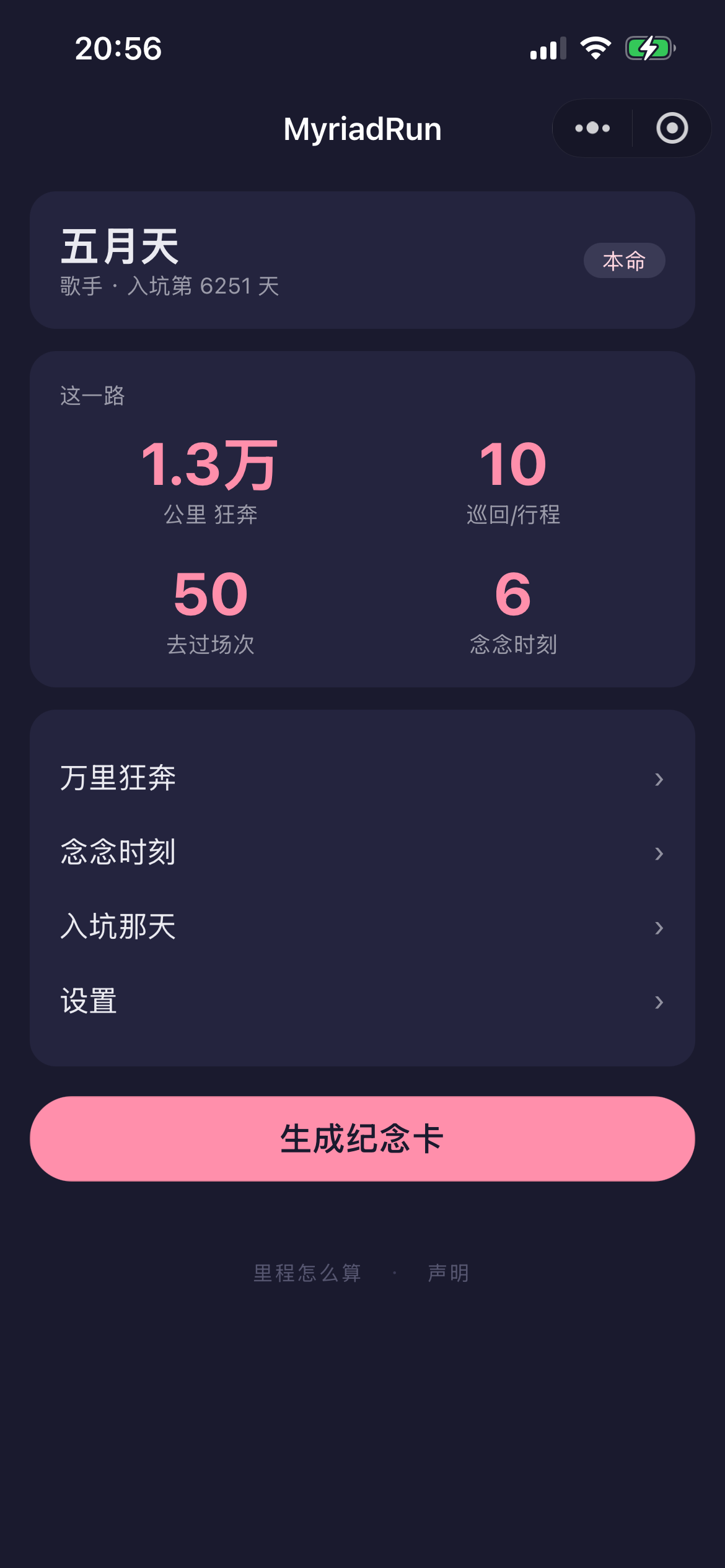
MyriadRun · 追星记录小程序
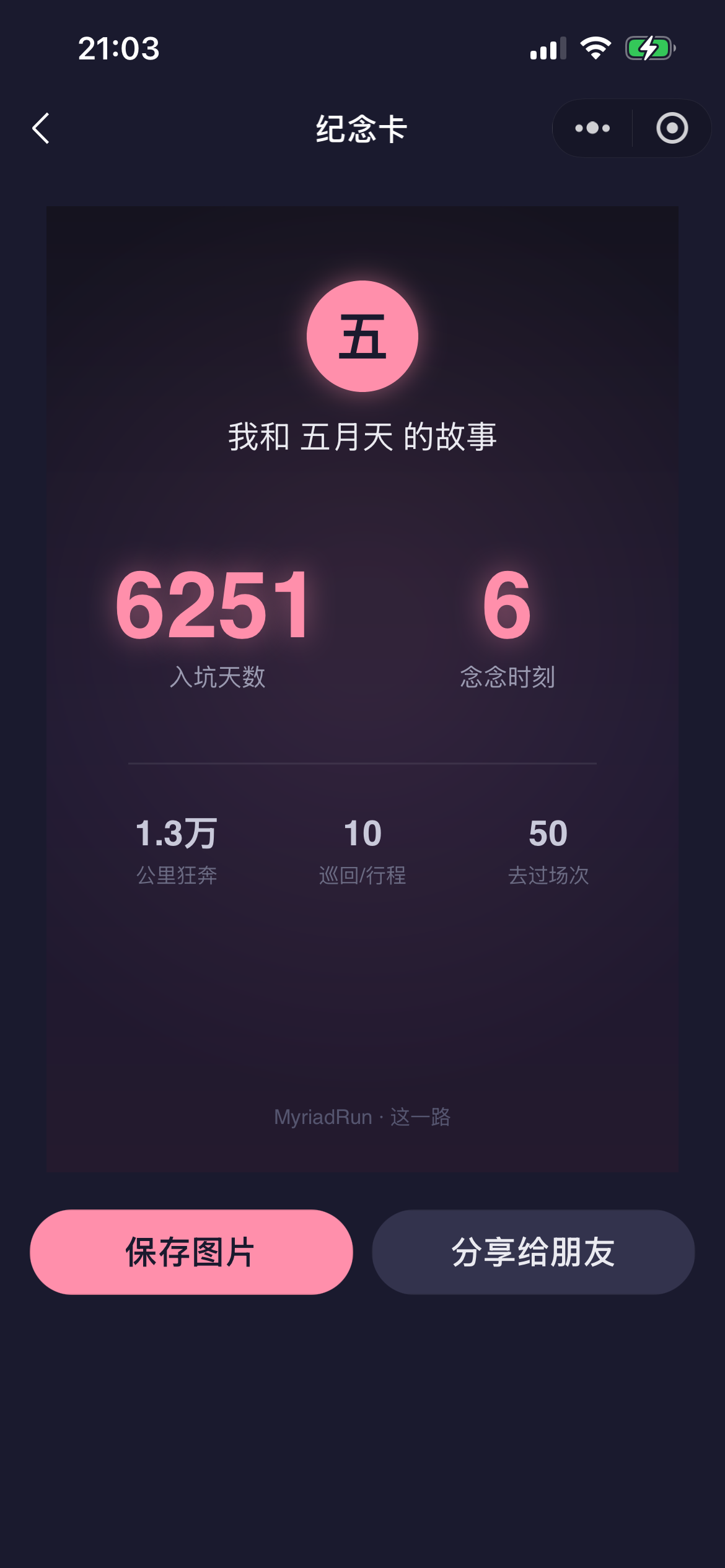
帮粉丝记录追星生活、量化"为 TA 奔波了多远"、一键生成纪念卡的微信小程序——但它反攀比:核心是记录自己,不是比谁去得多。
最关键决策:砍掉预置内容库
预置库体验最好但三大长期成本——持续人力维护、封面版权、冷启动流失。一人团队扛不起持续内容运营——这不是"做不出",是"判断不该做"。MVP 全部手动录入,预置库彻底砍掉。录入侧把边界处理做进 UI:
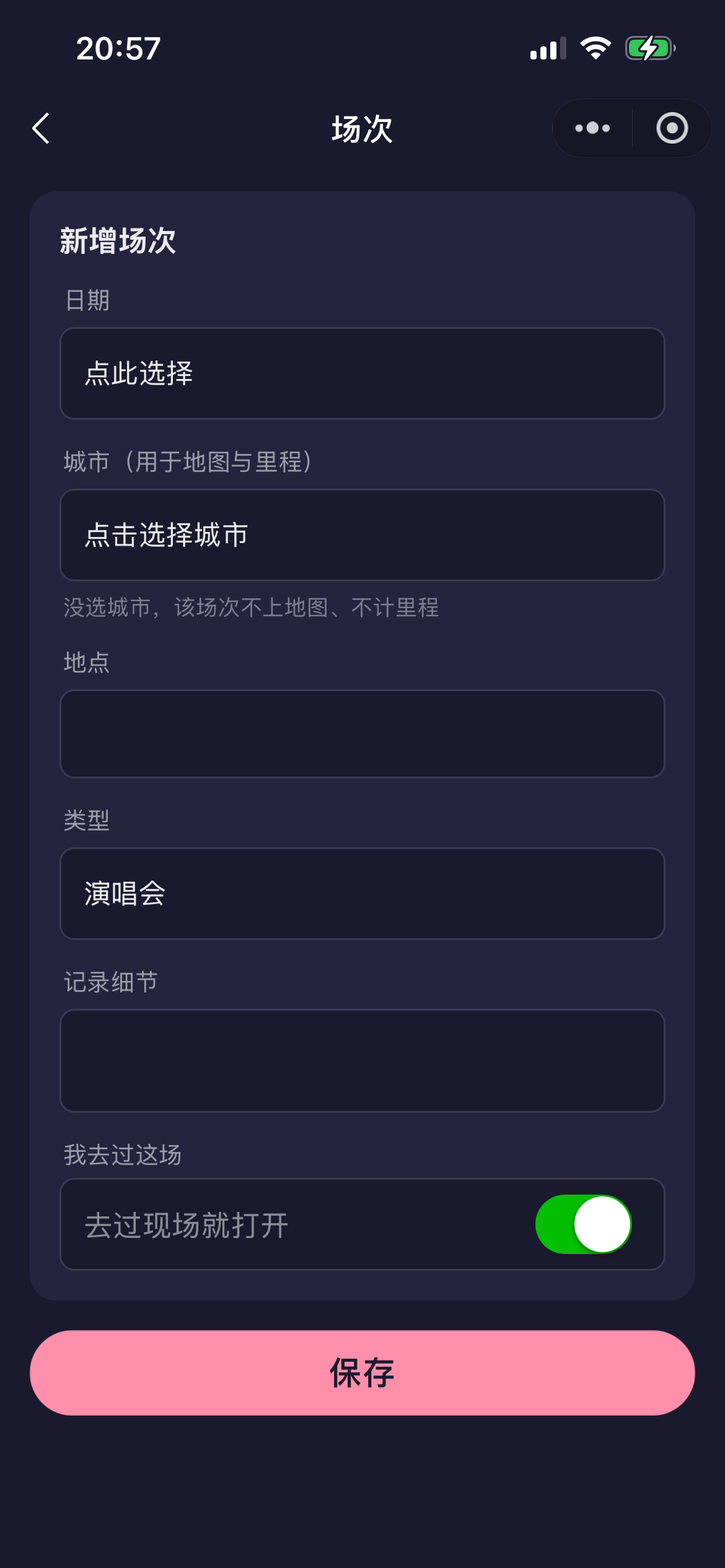
里程口径迭代 B → B′,并做成 app 内可见的诚信说明
初版 B(每场往返×2)在同城连开多场时不合理 → 改 B′:单程、同城多场按"趟"计、只算去过且选了城市的场次。这套口径用单测锁死(改动必须同步改测试)。更关键的是——把估算口径明明白白写给用户看:

反攀比的产品价值观(贯彻到交互)
全栈交付:canvas 自绘分享物(不引地图 SDK / 不引图表库)

工程硬约束
- CloudBase
.update()深合并-502001坑 → 坐标一律扁平标量存(lat/lng),踩一次后预判下一处提前修。 - 惰性创建修幽灵用户:拆
ensureUser为只查不建的getUser,落库挪到"提交本命"那刻。 - 核心纯逻辑(haversine / B′里程 / 纪念数据聚合 / 离线队列)33/33 单测全绿。
- 发布工程:微信四道闸 + 备案"服务内容标识"须与微信类目一致 + 6 集合权限"仅创建者可读写"(无服务端 app 唯一安全红线)。
digitme · Markdown → 配音解说视频自动管线
写一份带"配音脚本"的 Markdown,自动产出竖屏配音解说视频——克隆音色、硬烧字幕、零付费 API。这是作品集里唯一端到端完整跑通、产出过真实成品的项目。
input → output 对照
输入是一份双层 Markdown——可见部分给 Gamma 排版,每页一段 <!-- narration --> HTML 注释给本地 TTS 配音。一份文本同时驱动"排版"和"配音"两条流水线,互不干扰(Gamma 渲染时忽略 HTML 注释)。
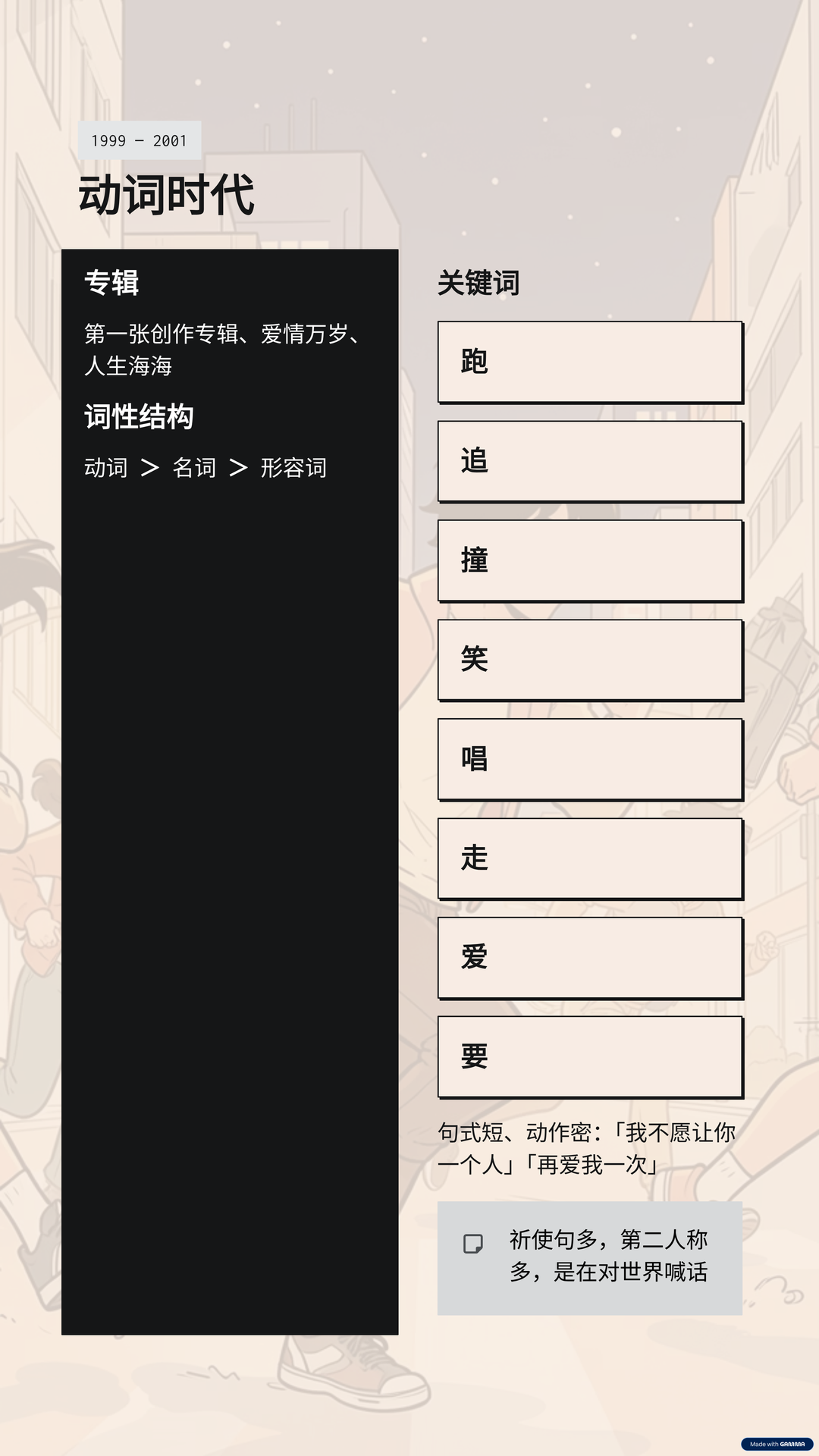
# 一九九九到二零零一|动词时代
- 专辑:第一张创作专辑、爱情万岁、人生海海
- 高频词性:动词 > 名词 > 形容词
- 关键词:跑、追、撞、笑、唱、走、爱、要
- 句式短、动作密:「我不愿让你一个人」「再爱我一次」
<!-- narration: 最早的三张专辑,动词的占比高到吓人。
歌词里全是跑、追、撞、笑、走、爱、要…… -->同一份 outline.md 跑出:规范化 1080×1920 slide PNG → CosyVoice 克隆音色配音 → 切句 SRT → ffmpeg 合成。完整成品视频 12MB / 9 页带配音带字幕。

核心工程决策
- 判断 HeyGen 付费数字人长期不可持续 → 自研 CosyVoice 本地方案。功能做减法(砍掉数字人只留配音)换长期零成本——这是产品判断不是技术妥协。
- 双 venv subprocess 架构:CosyVoice 依赖(torch/whisper/onnxruntime)与本项目冲突 → 单独装独立 venv,主流程用 subprocess 拉起 worker。关键坑固化在 CLAUDE.md:解析 venv python 路径必须
follow_symlinks=False,否则子进程sys.prefix指向系统 Python,CosyVoice 全 ModuleNotFoundError。 - 内容寻址缓存避免重复烧钱/重算,并兜底救回过一次事故:分镜/TTS/配图三类产物按
sha256(关键输入)缓存。一次误覆盖 outline.md,用.cache/tts/内容寻址逐段比对,9/12 段字节级命中,确认对话重建版本无损。 - 字幕字号的"魔法常数"钉进 CLAUDE.md:ffmpeg subtitles 滤镜从 SRT 转 ASS 时 PlayResY 默认 288,FontSize 在此坐标系计量。canvas 从横屏改竖屏后,font_size 数值不变但物理像素翻倍——这种不直观耦合写进文档防复踩。
- tag 前缀防覆盖:所有产物按
<project>_xxx命名——直接响应"绝不静默覆盖用户产物"原则(曾误覆盖过一次旧 wav,从此前缀隔离)。
跨平台 UGC 采集 + 静态化部署管线
把分散在 4 个技术栈完全不同的平台上的百万级公开 UGC,零失败率地采集、清洗、静态化并部署上线。
规模与可靠性
| 平台 | 规模 | 结果 |
|---|---|---|
| 论坛 A | 2095 个唯一帖 ID | 100% 处理:有效 1484 / 已删 618 / 真失败 0 / 遗漏 0,12 GB 快照 |
| 问答站 | 39 个高热回答 | 5,678 主层评论 + 36,076 子楼 + 25,492 图 URL |
| BBS B / C | 多板块万级帖 | 异构接口分别适配 |
最硬的一条:scraper 静默重定向污染检测
爬虫最危险的不是抓不到(会报错),是"看似抓到了,抓的是别的东西"——URL 失效后站点静默重定向到另一个页面,HTTP 200 + 数据完整,肉眼无法发现。
检测法:对同源多次抓取建立元素级唯一 ID 集合,跑两两交集——交集 ≥95% 即被重定向到那个兄弟页(实测一例 dataId 交集 148/150);与所有兄弟交集 0% 但元数据时间集中在某远年份 + 极低回复数 → 被重定向到了主页/错误页。几条 grep 就能跑出来,比人肉逐个验 URL 快一个量级。
这条决定了"零失败率"是真的,不是自我安慰——多数爬虫工程师只会处理"抓不到"(会报错的失败),想不到"抓到的是别的东西"(HTTP 200 但内容错位的失败)。
配套工程纪律
- 断点续跑契约:脚本第一行"已有文件就跳过"。长任务跨午夜 + 关机重启 + 误删 + 浮层被关多次,最终 2095 个 ID 全到——靠的就是这条契约,不是"一次跑完别出事"的侥幸。
- 风控误报 vs 真风控的判别:captcha 正则一度过宽(正文出现"安全检查"四字就触发,实为登机流程描述)。判别法:直接 CDP 拉
document.title看真实页面状态——能正常加载就是脚本误判,加载不出才是真风控。 - 多站异构适配:4 个源技术栈完全不同——问答站需 CDP 登录态 + 嵌套滚动容器;BBS 用 trafilatura 抽正文 + 固定短 UA;新版论坛切 nForum 接口 + cookie;删除帖走 Wayback CDX 拉历史快照差集。没有"一个爬虫打天下"。
- 大文本数据工程纪律:百万级文本绝不全量进上下文/内存;脚本筛元数据落盘成索引,按键回查原文件。
- 静态化部署工程:CF Pages 20k 文件 / 25MB 单文件硬上限 → 字体子集化(GB2312 一二级 6763 字)+ Variable Font 单文件 + 多项目拆分 +
cp -al零拷贝 staging dist。另踩并解掉 Three.js 3D 展厅"每图配独立 SpotLight = O(N²) shader 灾难"。
联系
欢迎讨论任何 AI 应用工程 / AI 解决方案方向的机会。
- 邮箱:yangrongyangdan@126.com
- 所在地:北京(可深圳)